#Apache PDFBox
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Forty percent of Tumblr users are between the ages of 18 to 25.
Text
ZUGFeRD mit PHP: Wie ich das horstoeko/zugferd-Paket lokal vorbereitet und ohne Composer-Zugriff auf den Server gebracht habe
Wer schon einmal versucht hat, das ZUGFeRD-Format mit PHP umzusetzen, wird früher oder später auf das Projekt **horstoeko/zugferd** stoßen. Es bietet eine mächtige Möglichkeit, ZUGFeRD-konforme Rechnungsdaten zu erstellen und in PDF-Dokumente einzubetten. Doch gerade am Anfang lauern einige Stolpersteine: Composer, Pfadprobleme, Server ohne Shell-Zugriff. Dieser Beitrag zeigt, wie ich mir mit einem lokalen Setup, GitKraken und einem simplen Upload-Trick geholfen habe, um trotz aller Einschränkungen produktiv arbeiten zu können. Bevor ich das Paket überhaupt einbinden konnte, musste Composer einmal lokal installiert werden – ganz ohne kommt man nicht aus. Ich habe mich für den Weg über die offizielle Installationsanleitung entschieden:
php -r "copy('https://getcomposer.org/installer', 'composer-setup.php');" php composer-setup.php php -r "unlink('composer-setup.php');"
Es gibt aber auch fertige Pakete als *.exe für Windows. ### GitKraken, Composer & das Terminal Ich arbeite gerne visuell, und daher ist **GitKraken** mein bevorzugter Git-Client. Doch ein oft unterschätzter Vorteil: GitKraken bringt ein eigenes Terminal mit. Dieses habe ich genutzt, um **Composer lokal** zu verwenden – ohne die globale Composer-Installation auf meinem Server-System anfassen zu müssen.
# Im Terminal von GitKraken composer require horstoeko/zugferd
Dabei habe ich mich bewusst für die `1.x`-Version entschieden, da diese eine stabilere und besser dokumentierte Grundlage für den Einsatz ohne komplexes Setup bietet. Zudem ist dort der `ZugferdDocumentPdfBuilder` enthalten, der es erlaubt, das gesamte PDF-Handling im PHP-Kosmos zu belassen. Soweit ich gesehen habe, gibt es wohl auch DEV-Versionen, aber ich war mir nicht sicher wie weit diese nutzbar sind. ### Der Upload-Trick: Alles lokal vorbereiten Da mein Zielserver keinen Composer-Zugriff bietet, musste ich alles **lokal vorbereiten**. Ich nutze für meine Testumgebung einen einfachen Server von AllInk. Das ist extrem kostengünstig, aber eigene Software installieren, Fehlanzeige. Der Trick: Ich habe den gesamten `vendor`-Ordner inklusive `composer.json` und `composer.lock` gezippt und manuell auf den Server übertragen. Das spart nicht nur Zeit, sondern funktioniert in jeder Hostingumgebung.
# Lokaler Aufbau my-project/ ├── src/ ├── vendor/ ├── composer.json ├── composer.lock
Dann per SFTP oder FTP hochladen und sicherstellen, dass im PHP-Code folgender Autoloader korrekt eingebunden wird:
require __DIR__ . '/vendor/autoload.php';
### Vorsicht, Pfade: Die Sache mit dem "/src"-Unterordner Ein Stolperstein war die Struktur des horstoeko-Pakets. Die Klassen liegen nicht direkt im Projektverzeichnis, sondern verstecken sich unter:
/vendor/horstoeko/zugferd/src/...
Der PSR-4-Autoloader von Composer ist darauf vorbereitet, aber wer manuell Klassen einbindet oder den Autoloader nicht korrekt referenziert, bekommt Fehler. Ein Test mit:
use horstoeko\zugferd\ZugferdDocumentPdfBuilder;
funktionierte erst, nachdem ich sicher war, dass der Autoloader geladen war und keine Pfade fehlten. ### Endlich produktiv: Der erste Builder-Lauf Nachdem alles hochgeladen und die Autoloading-Probleme beseitigt waren, konnte ich mein erstes ZUGFeRD-Dokument bauen:
$builder = new ZugferdDocumentPdfBuilder(); $builder->setDocumentFile("./rechnung.pdf"); $builder->setZugferdXml("./debug_12345.xml"); $builder->saveDocument("./zugferd_12345_final.pdf");
Und siehe da: eine ZUGFeRD-konforme PDF-Datei, direkt aus PHP erzeugt. Kein Java, kein PDF/A-Tool von Adobe, keine Blackbox. Wichtig, das ganze ist per ZIP auf jeden Kundenserver übertragbar. ### Warum kein Java? Ich habe bewusst darauf verzichtet, Java-Tools wie Apache PDFBox oder gar die offizielle ZUGFeRD Java Library zu nutzen – aus einem ganz einfachen Grund: Ich wollte die Lösung so nah wie möglich an meiner bestehenden PHP-Infrastruktur halten. Keine zusätzliche Runtime, keine komplexen Abhängigkeiten, keine Übersetzungsprobleme zwischen Systemen. PHP allein reicht – wenn man die richtigen Werkzeuge nutzt. ### Häufige Fehlermeldungen und ihre Lösungen Gerade beim Einstieg in das horstoeko/zugferd-Paket können einige typische Fehlermeldungen auftreten: **Fehler:** `Class 'horstoeko\zugferd\ZugferdDocumentPdfBuilder' not found`
// Lösung: require_once __DIR__ . '/vendor/autoload.php';
**Fehler:** `Cannot open file ./debug_12345.xml`
// Lösung: Pfad prüfen! Gerade bei relativen Pfaden kann es helfen, alles absolut zu machen: $builder->setZugferdXml(__DIR__ . '/debug_12345.xml');
**Fehler:** `Output file cannot be written`
// Lösung: Schreibrechte auf dem Zielverzeichnis prüfen! Ein chmod 775 oder 777 (mit Bedacht!) kann helfen.
--- **Fazit:** Wer wie ich auf Servern ohne Composer arbeiten muss oder will, kann sich mit einem lokalen Setup, GitKraken und einem Zip-Upload wunderbar behelfen. Wichtig ist, auf die Pfade zu achten, den Autoloader korrekt einzubinden und nicht vor kleinen Hürden zurückzuschrecken. Die Möglichkeiten, die das horstoeko/zugferd-Paket bietet, machen die Mühe mehr als wett. Zumal das ganze Setup, 1 zu 1, auf einen Kundenserver übertragen werden kann. Die eigentlichen Daten kommen aus FileMaker, dieser holt sich die PDF und das XML auch wieder vom Server ab. Somit ist die Erstellung der ZUGFeRD-PDF und der XML mit einen FileMaker-Script abzudecken. Für die Erstellung auf dem Server bedarf es zweier PHP-Scripte. Dazu das Horstoeko/zugferd-Paket.
0 notes
Link

PDF stands for Portable Document Format. It is a file format which is used to display a printed document in digital form. It is independent of the environment in which it was created or the environment in which it is viewed or printed.
It is developed and specified by Adobe® Systems as a universally compatible file format based on the PostScript format.
0 notes
Text
Extract PDF embedded fonts as TrueTypeFonts (with a .ttf file extension) for installation onto your PC— steps for font installation are as follows:
Select [Control Panel] - (Appearance and Personalization) - [Fonts] - Drag .ttf files into folder
0 notes
Text
Crear PDF con PDFBox en Java
Crear PDF con PDFBox en Java
PDFBOX es una libreria para crear PDFs en Java, es una libreria del Apache Project, por lo que es software libre , esta muy bien documentada y tiene una gran comudidad para resolver problemas y dudas. (more…)
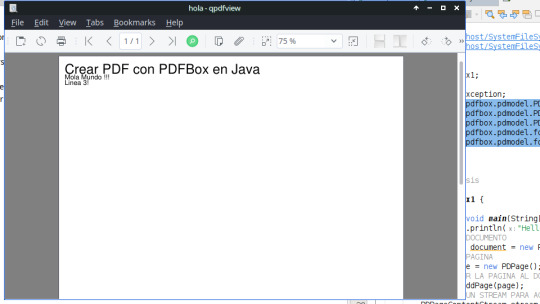
View On WordPress
0 notes
Quote
Apache PDFBox は比較的新しいライブラリで、Version 1.0.0 は2010年にリリースされ、2017年01月現在の最新は 2.0.4 です。 Version 1 は、日本語などのマルチバイト文字に対応していませんでしたが、2016年にリリースされた Version 2 から日本語にも対応しましたので、日本国内の開発での選択肢となるかと思います。 名前の通り、The Apache Software Foundation のもとで開発が行われており、ライセンスは Apache License, Version 2.0 です。 PDFBox には、PDF の作成、PDF からテキストを抽出、暗号化/復号化, イメージのPDF変換、イメージの抽出 などの機能が実装されています。
Java ライブラリ Apache PDFBox で PDF を操作しよう (第1回:概要と簡単な操作) | WEB ARCH LABO
1 note
·
View note
Text
Show HN: Parsing horse racing charts with Apache PDFBox
https://github.com/robinhowlett/chart-parser Comments
1 note
·
View note
Text
Apache PDFBox Page Tree Parsing Denial of Service Vulnerability
SNNX.com : http://dlvr.it/QmmpHY
0 notes
Text
How to extract text line by line from PDF document
How to extract text line by line from PDF document
Apache PDFBox Tutorial – We shall learn how to extract text line by line from PDF document (from all the pages) either by using writeText method or getText method of PDFTextStripper.
Method 1 – Use PDFTextStripper.getText to extract text line by line from PDF document
You may use the getText method of PDFTextStripper that has been used in extracting text from pdf. Then splitting the text string…
View On WordPress
0 notes
Link
Article URL: https://github.com/robinhowlett/chart-parser
Comments URL: https://news.ycombinator.com/item?id=14718485
Points: 24
# Comments: 1
0 notes
Text
Could this tool for the dark web fight human trafficking and worse?
In today’s data-rich world, companies, governments and individuals want to analyse anything and everything they can get their hands on – and the World Wide Web has loads of information.
At present, the most easily indexed material from the web is text.
But as much as 89 to 96 percent of the content on the internet is actually something else – images, video, audio, in all thousands of different kinds of non-textual data types.
Further, the vast majority of online content isn’t available in a form that’s easily indexed by electronic archiving systems like Google’s.
Rather, it requires a user to log in, or it is provided dynamically by a program running when a user visits the page.
If we’re going to catalog online human knowledge, we need to be sure we can get to and recognise all of it, and that we can do so automatically.
How can we teach computers to recognise, index and search all the different types of material that’s available online?
Thanks to federal efforts in the global fight against human trafficking and weapons dealing, my research forms the basis for a new tool that can help with this effort.
Understanding what’s deep
The “deep web” and the “dark web” are often discussed in the context of scary news or films like “Deep Web,” in which young and intelligent criminals are getting away with illicit activities such as drug dealing and human trafficking – or even worse.
But what do these terms mean?
The “deep web” has existed ever since businesses and organisations, including universities, put large databases online in ways people could not directly view.
Rather than allowing anyone to get students’ phone numbers and email addresses, for example, many universities require people to log in as members of the campus community before searching online directories for contact information.
Online services such as Dropbox and Gmail are publicly accessible and part of the World Wide Web – but indexing a user’s files and emails on these sites does require an individual login, which our project does not get involved with.
The “surface web” is the online world we can see – shopping sites, businesses’ information pages, news organisations and so on.
The “deep web” is closely related, but less visible, to human users and – in some ways more importantly – to search engines exploring the web to catalog it.
I tend to describe the “deep web” as those parts of the public internet that:
Require a user to first fill out a login form,
Involve dynamic content like AJAX or Javascript, or
Present images, video and other information in ways that aren’t typically indexed properly by search services.
What’s dark?
The “dark web,” by contrast, are pages – some of which may also have “deep web” elements – that are hosted by web servers using the anonymous web protocol called Tor.
Originally developed by US Defence Department researchers to secure sensitive information, Tor was released into the public domain in 2004.
Like many secure systems such as the WhatsApp messaging app, its original purpose was for good, but has also been used by criminals hiding behind the system’s anonymity.
Some people run Tor sites handling illicit activity, such as drug trafficking, weapons and human trafficking and even murder for hire.
The US government has been interested in trying to find ways to use modern information technology and computer science to combat these criminal activities.
In 2014, the Defence Advanced Research Projects Agency (more commonly known as DARPA), a part of the Defence Department, launched a program called Memex to fight human trafficking with these tools.
Specifically, Memex wanted to create a search index that would help law enforcement identify human trafficking operations online – in particular by mining the deep and dark web.
One of the key systems used by the project’s teams of scholars, government workers and industry experts was one I helped develop, called Apache Tika.
The ‘digital Babel fish’
Tika is often referred to as the “digital Babel fish,” a play on a creature called the “Babel fish” in the “Hitchhiker’s Guide to the Galaxy” book series.
Once inserted into a person’s ear, the Babel fish allowed her to understand any language spoken.
Tika lets users understand any file and the information contained within it.
When Tika examines a file, it automatically identifies what kind of file it is – such as a photo, video or audio.
It does this with a curated taxonomy of information about files: their name, their extension, a sort of “digital fingerprint”.
When it encounters a file whose name ends in “.MP4” for example, Tika assumes it’s a video file stored in the MPEG-4 format.
By directly analysing the data in the file, Tika can confirm or refute that assumption – all video, audio, image and other files must begin with specific codes saying what format their data is stored in.
Once a file’s type is identified, Tika uses specific tools to extract its content such as Apache PDFBox for PDF files, or Tesseract for capturing text from images.
In addition to content, other forensic information or “metadata” is captured including the file’s creation date, who edited it last, and what language the file is authored in.
From there, Tika uses advanced techniques like Named Entity Recognition (NER) to further analyse the text.
NER identifies proper nouns and sentence structure, and then fits this information to databases of people, places and things, identifying not just whom the text is talking about, but where, and why they are doing it.
This technique helped Tika to automatically identify offshore shell corporations (the things); where they were located; and who (people) was storing their money in them as part of the Panama Papers scandal that exposed financial corruption among global political, societal and technical leaders.
Tika extracting information from images of weapons curated from the deep and dark web. Stolen weapons are classified automatically for further follow-up.
Identifying illegal activity
Improvements to Tika during the Memex project made it even better at handling multimedia and other content found on the deep and dark web.
Now Tika can process and identify images with common human trafficking themes.
For example, it can automatically process and analyse text in images – a victim alias or an indication about how to contact them – and certain types of image properties – such as camera lighting.
In some images and videos, Tika can identify the people, places and things that appear.
Additional software can help Tika find automatic weapons and identify a weapon’s serial number.
That can help to track down whether it is stolen or not.
Employing Tika to monitor the deep and dark web continuously could help identify human- and weapons-trafficking situations shortly after the photos are posted online.
That could stop a crime from occurring and save lives.
Memex is not yet powerful enough to handle all of the content that’s out there, nor to comprehensively assist law enforcement, contribute to humanitarian efforts to stop human trafficking and even interact with commercial search engines.
It will take more work, but we’re making it easier to achieve those goals.
Tika and related software packages are part of an open source software library available on DARPA’s Open Catalog to anyone – in law enforcement, the intelligence community or the public at large – who wants to shine a light into the deep and the dark.
Christian Mattmann is a principal data scientist and the chief architect in the Instrument and Data Systems section at the Jet Propulsion Laboratory in California.
This article was originally published on The Conversation.
Follow StartupSmart on Facebook, Twitter, LinkedIn and iTunes.
The post Could this tool for the dark web fight human trafficking and worse? appeared first on StartupSmart.
from StartupSmart http://www.startupsmart.com.au/technology/could-this-tool-for-the-dark-web-fight-human-trafficking-and-worse/
0 notes
Text
NA CVE201811797 In Apache PDFBox 1.8.0 to 1.8.15 and 2.0.0RC1.
SNNX.com : NA CVE201811797 In Apache PDFBox 1.8.0 to 1.8.15 and 2.0.0RC1. http://dlvr.it/QmSc8Y
0 notes
Text
Apache PDFBox 1.8.14 2.0.10 Denial Of Service
SNNX.com : http://dlvr.it/QZQzXj
0 notes
Text
Bugtraq CVE20188036 DoS OOM Vulnerability in Apache PDFBoxs AFMParser
SNNX.com : Bugtraq CVE20188036 DoS OOM Vulnerability in Apache PDFBoxs AFMParser http://dlvr.it/QZK2yJ
0 notes
Text
How to extract words from PDF document
How to extract words from PDF document
Apache PDFBox Tutorial – We shall learn how to extract words from PDF document (from all the pages) using writeText method of PDFTextStripper.
The class org.apache.pdfbox.contentstream.PDFTextStripper strips out all of the text.
To extract extract words from PDF document, we shall extend this PDFTextStripper class, intercept and implement writeString(String str, List textPositions) method.
The…
View On WordPress
0 notes
Text
How to extract co-ordinates or position of characters in PDF - PDFBox
How to extract co-ordinates or position of characters in PDF – PDFBox
Apache PDFBox Tutorial – We shall learn how to extract co-ordinates or position of characters in PDF from all the pages using PDFTextStripper.
The class org.apache.pdfbox.contentstream.PDFTextStripper strips out all of the text.
To get co-ordinates or location and size of characters in pdf, we shall extend this PDFTextStripper class, intercept and implement writeString(String string, List…
View On WordPress
0 notes